Published
-
RL

Defination
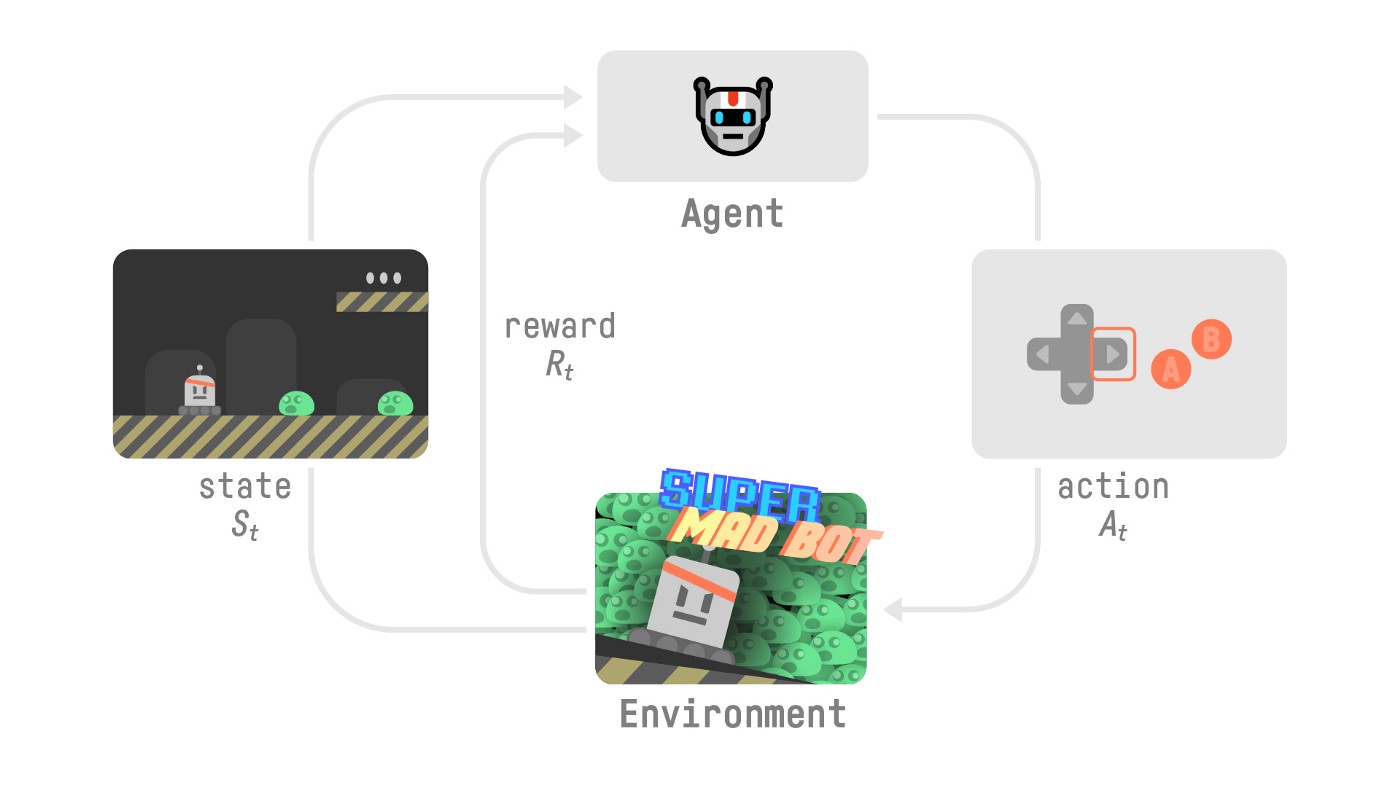
Reinforcement learning is a framework for solving control tasks (also called decision problems) by building agents that learn from the environment by interacting with it through trial and error and receiving rewards (positive or negative) as unique feedback.
-
Policy(策略函数): The agent’s behavior function, which is a mapping from states to actions.
- on-policy: The policy is the same as the policy used to generate the data.
- off-policy: The policy is different from the policy used to generate the data.
-
Goal: Maximize the expected return
-
Markov Decision Process(MDP): The agent needs only the current state (not the history of states/actions) to decide a movement.

Q-learning
Value Function

- state->value function
- state->(action-value) function
Bellman Equation
It’s like dynamic programming.

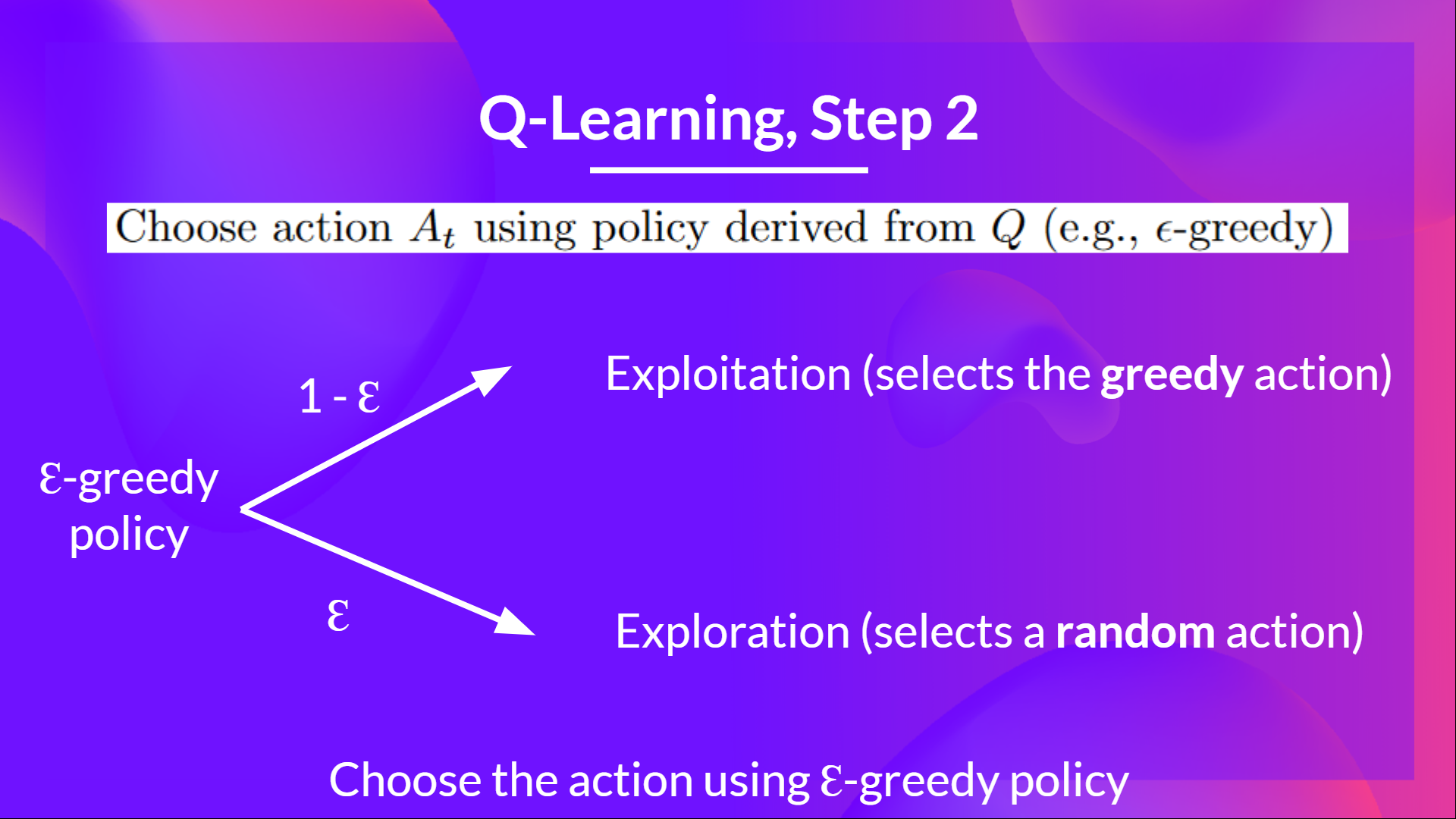
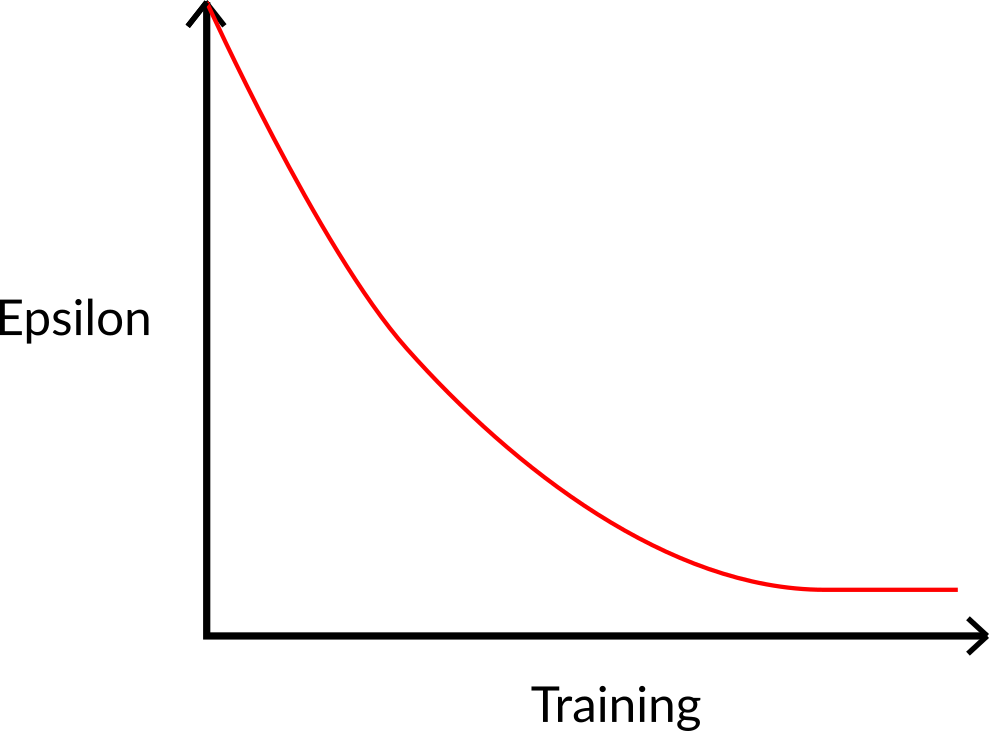
Epsilon greedy strategy
A policy that alternates between exploration (random actions) and exploitation.
Learning
Monte Carlo
Learning at the end of the episode.

- the balance can be reached as the value grow along with the reward
Temporal Difference
 is replaced by , which is the TD target implying the estimated return.
is replaced by , which is the TD target implying the estimated return.
Q-learning
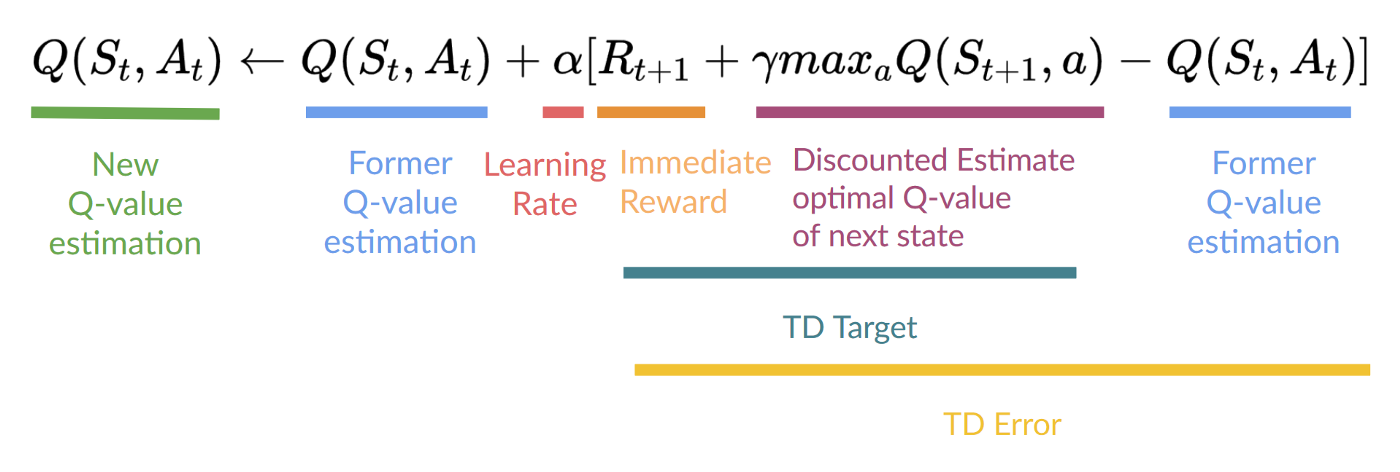
- Notice the TD Error. It’s similar to the loss function in deeplearnig.(difference between the predicted and the target).
- The difference: TD Error is not a supervised signal, it’s a difference between the predicted and the target, and the target is continuous updated according to the far end of rewards.
- It’s like far->near(down->top) hireachy.
DQN
Combine Q-learning with deep learning.
Optimization
Experience Replay
- Problem: The catasphic interference.
- Avoid forgetting previous experiences (aka catastrophic interference, or catastrophic forgetting) and reduce the correlation between experiences.
- The problem we get if we give sequential samples of experiences to our neural network is that it tends to forget the previous experiences as it gets new experiences
- Make more efficient use of the experiences during the training

Fixed Q-targets
-
Problem: The Q-network is unstable.(参数相互依赖)
-
Use a separate network with fixed parameters for estimating the TD Target.
-
Copy the parameters from our Deep Q-Network every C steps to update the target network.
Double DQN
-
Problem: If non-optimal actions are regularly given a higher Q value than the optimal best action, the learning will be complicated.
-
Solution: use two networks to decouple the selection of the action and the evaluation of the action.(解藕)
-
The double DQN is a kind of regularization to the DQN.
actually, double DQN is similar to Fixed Q-targets. it’s like a checkpoints netword instead of a separate network.
Policy Gradient
From value-based to policy-based.
In value-based methods, policy is simple(greedy). The key is to estimate the value function.
But in policy-based methods, we want to learn the policy directly.
Policy Gradient Theorem
 -> Gradient needs to add a ’-’ as the torch acts better with gradient descent than gradient ascent.
-> Gradient needs to add a ’-’ as the torch acts better with gradient descent than gradient ascent.
Multi-agent RL
- Reward engineering problem:
- Having a too complex reward function to force your agent to behave as you want it to do.
- Why? Because by doing that, you might miss interesting strategies that the agent will find with a simpler reward function.
Curiosity
- Sparse rewards problem: most rewards do not contain information, and hence are set to zero.
- The extrinsic reward function is handmade
Actor-Critic methods
- An Actor that controls how our agent behaves (Policy-Based method)
- A Critic that measures how good the taken action is (Value-Based method)